عبارت منظم (Regular Expression)
عبارت منظم در واقع یک «فرمول» یا الگو است که با استفاده از نمادهای الفبا و عملگرها، مجموعهای از رشتههای مجاز را تعریف میکند.
- اجزای تشکیلدهنده: شامل حروف الفبا، پرانتز و عملگرهایی نظیر الحاق(+(البته بصورت توان))، اجتماع (+) و ستاره (*) است.
- عملگر الحاق (+): به معنای تکرار «یک یا چند بار» است.
- عملگر ستاره (*): به معنای تکرار «صفر یا چند بار» است.
مثال:
فرض کن الفبای ما $\{a, b\}$ باشد و عبارت منظم ما به صورت زیر باشد: $$r = a^*b$$
شرح: این عبارت میگوید هر تعدادی که دوست داری حرف $a$ بیاور (حتی میتوانی هیچ $a$ای نیاوری)، اما در انتها حتماً باید دقیقاً یک حرف $b$ قرار بگیرد.
- رشتههای مقبول:
$$b, ab, aab, aaab, \dots$$
زبان منظم (Regular Language)
به زبانی که بتوان برای آن یک «عبارت منظم» نوشت، زبان منظم گفته میشود. در واقع، زبان منظم مجموعهای از تمام رشتههایی است که از یک الگوی منظم پیروی میکنند.
مثال:
زبانی را در نظر بگیر که تمام رشتههای آن با حرف $a$ شروع میشن و با حرف $b$ تمام روی الفبای $\{a, b\}$. $$L = \{ab, aab, abb, abab, \dots\}$$ شرح: چون ما میتونیم برای این زبان عبارت منظم $a(a+b)^*b$ را بنویسیم، پس این زبان یک زبان منظم است.
مثال:
همچنین زبان را میتوان به شکل ریاضی هم نیز بیان کرد مثل زیر: $$L = \{a^n b^n | n \ge 0\}$$ الان این عبارت ریاضی دارد میگوید زبان $L$ برابر است با $a$ به توان $n$ و $b$ نیز به توان $n$ بطوری که n بزرگتر و مساوی با صفر است برای اینکه متوجه بشیم ایا این یک زبان منظم است یا مستقل از متن ابتدا باید یک سوال را از خودمان بپرسیم.
آیا میتونم این زبان رو به شکل یک عبارت منظم بنویسم یا نه؟
اگه شد نوشت که بله این یک زبان منظم است و اما اگر نشد نوشت قطعا مستقل از متن است که در ادامه یادش میگیریم. خب الان ایا این زبان رو میشه بصورت یک عبارت منظم نوشت؟ پاسخ: خیر منظم نیست. خب حالا چرا؟ چونکه تعداد $b$ ها باید با تعداد $a$ ها برابر باشد و این موضوع را نمیتوان با استفاده از عبارات منظم بیان کرد. توضیح بیشتر: نگاه کن فرض کن مقدار $n$ باشه 5 یعنی اول بیا پنجپ تا $a$ بزار بعدش هم پنج تا $b$ اگر دقت کنی انگار برای نمایش این زبان باید بشماریم چند $a$ میگذاریم که به همان تعداد هم بعد $a$ ها $b$ بگذاریم. خب ما اصلا به هیچ وجه نمیتونیم اینو با عملگر های ساده الحاق و استار در زبان منظم نمایش بدیم. بذار خیالت رو راحت کنم هر موقع حس کردی برای نمایش یک زبان انگار باید بشماریم شک نکن اون زبان منظم نیست چون عبارات منظم خیلی سادن و نمیتونن چنین زبان هایی رو نمایش بدن حالا برای اینکه بهتر متوجه بشی به مثال پایین دقت کن. $$L = \{a^n b^m | n \ge 0, m \ge 0\}$$ خب در رابطه با این چطور. ایا این منظم هست یا نه؟ جواب اینه که بله منظمه. چون که این زبان دقیقا عبارت منظم پایین هست: $$r = a^* b^*$$
خبالان فهمیدی چرا عبارت اولی یک زبان منظم نبود اما دومی بود.
گرامر (Grammar)
اگر اتوماتای ابزاری برای «تشخیص» رشتهها باشن، گرامر ابزاری برای «تولید» آنهاست. هر گرامر از چهار بخش اصلی تشکیل شده:
- V: مجموعه متغیرها (نمادهای غیرترمینال).
- T: مجموعه ترمینالها (حروف الفبای نهایی).
- S: متغیر شروع.
- P: قوانین تولید (دستورالعملهای ساخت رشته).
مثال:
گرامر ساده زیر رو در نظر بگیر: $$S \rightarrow aS$$ $$S \rightarrow b$$ شرح: در اینجا $S$ متغیر شروع ماست(یعنی همون V)چون میتونه تغییر کنه. میتونه $aS$ جاش قرار بگیره یا میتونه $b$ جاش قرار بگیره.و اما مجموعه ترمنال کدوما هستن. خب عارضم به حضورت که $a$ و $b$ ترمینال های ما هستن. ترمینال در زبان فارسی میشه پایانه. اینجا هم دقیقا به همون معناست هستند خاتمه دهنده هستن(میان جای متغییر ها قرار میگیرن). قانون اول میگه میتونی به هر تعداد که بخوای $a$ تولید کنی. قانون دوم میگه برای تمام کردن کار، باید یک $b$ بذاری. این گرامر رشتههایی مثل $b$، $ab$ و $aab$ رو تولید میکنه.
گرامر منظم (Regular Grammar)
گرامر منظم نوع خاصی از گرامر است که محدودیتهای بیشتری دارد تا دقیقاً همان زبانهای منظم را تولید کند. در این گرامرها، در سمت چپ هر قانون فقط باید «یک متغیر» وجود داشته باشد. همچنین قوانین باید به گونهای باشند که متغیرها یا در ابتدای رشته بیایند یا در انتهای آن (بسته به نوع گرامر).
مثال:
به قوانین تولید زیر دقت کن: $$S \rightarrow aB$$ $$B \rightarrow b$$ شرح: این یک گرامر منظم است چون در سمت چپ هر قانون فقط یک متغیر ($S$ یا $B$) داریم و در سمت راست، یک حرف ترمینال ($a$) آمده که به دنبال آن یک متغیر ($B$) ظاهر شده است. این ساختار خطی، ویژگی اصلی گرامرهای منظم است. خیلی ساده تر برات بگم گرامر های منظم:
-
در سمت راست قاون فقط یک متغییر دارن: $$S \rightarrow aB$$ $$S \rightarrow Ba$$
-
یا هم متغییر ندارن و به ترمینال خالی ختم میشه: $$S \rightarrow a$$
غیر از این حالت ها بود منظم نیست. در اصل برای تخیص دادن اینکه ایا منظم هست یا نه باید به سمت راست قوانین نگاه کنی و این نکته رو همیشه یادت باشه داخل گرامر چه منظم و چه مستقل از متن در سمت چپ فقط و فقط یک متغییر داریم.
ماشین(اتوماتای)
- ماشین ها یا به عبارتی اتوماتای ها ابزاری هستن برای اینکه ما یک رشته از یک زبان رو به عنوان ورودی بهشون بدیم و اونها تشخیص بدن ایا این رشته جزو زبان هست یا نه.
- بخوام خیلی ساده و محاوره ای توضیح بدم اتوماتای کاری که انجام میدن مثل این میمونه که ما یه اتوماتای داشته باشی که کلمه بهش میدیم و اون تشخیص بده ایا این کلمه لری هست یا نه.
- در دنیای کامپیوتر اتوماتای مثل ابزار های تشخیص syntax در VScode عمل میکنن. به این صورت که خط کد ها کاراکتر به کاراکتر به عنوان عروردی بهش پاس داده میشه و برای مثال اگر بعد از باز شدن پرانتز . پرانتز بسته ای پیدا نشود ارور میدهد که یعنی این رشته جزو ورودی های مجاز نیست.
انواع اتوماتای
-
متناهی(FA)
- این ماشین ها خیلی سادن و حافظه هم ندارن و فقط میتونن پذیرش یا عدم پذیرش یک رشته از زبان منظم مورد نظر را تعیین کند.
- این ماشین فقط قادر به تشخیص زبان های منظم هست
- این اتوماتای دو نوع داره
- DFA(متناهی معین): همینقدر تا اینجا بلد باش که در ان ماشین ها اول اینکه هیچ حالتی کاراکتر خالی نمیپذیره و همچنین یک حالت با دریافت کاراکتری مثل $a$ فقط میتونه به یک حالت دیگه بره.
- NFA(متناهی نامعین): خب اونحدودیت هایی که برای DFA گفتم رو برداریم بندازیم دور میشه NFA. یعنی کاراکتر خالی یا به عبارتی هیچی رو حالت ها میپذیرن و اینکه از یک حالت با دیدن هر کاراکتری مثل $a$ میشه به چند حالت دیگر رفت و محدودیتی نداره.
-
پشتهای(PDA)
- خیلی خیلی ساده بگم این اتوماتای همون NFA هست فقط یدونه حافظه استک هم داره که جلو تر میبینیم چطوری کار میکنه.
- از این اتوماتای برای تشخیص زبان های مستقل از متن استفاده میشه.
-
(TM)ماشین تورینگ
- این ماشین پیشرفته ترین ماشینی هست که داخل این درس باهاش سر و کار داریم و هم میتونه رشته بنویسه(تولید کنه) هم میتونه رشته بخونه(تشخیص بده) که اخرین درس هست و بعدا باهاش اشنا میشیم.
مؤلفههای هر اتوماتای:
مجموعه حالات $$Q$$ الفبا (نمادهای ورودی) $$\Sigma$$ تابع انتقال $$\delta$$ حالت شروع $$q_0$$ مجموعه حالات پذیرش (پایانی) $$F$$
- اگه متوجه نمیشی اینا چین صبر داشته باش
DFA
- بیا با یه مثال پیش بریم
- خب همونطور که گفتیم از اتوماتای متناهی یعنی DFA برای تشخیص زبان های منظم استفاده میکنیم.
خب من الان میخوام بیام یک اتوماتای بنویسم که تمام رشته های عبارت منظم و معروف زیر رو تشخیص بده
$$r = a^*b$$
خب ما میدونیم که این عبارت منظم رشته های زیر رو تولید میکنه
$$b, ab, aab, aaab, aaaab, \dots$$
یا به عبارت دیگه
$$L = \{a^n b | n \ge 0\ \}$$
خب الان ما میخوام اتوماتایی بسازیم که رشته های این زبان رو به عنوان ورودی بگیره و تشخیص بده ایا رشته ورودی جزو رشته های این زبان هست یا نه
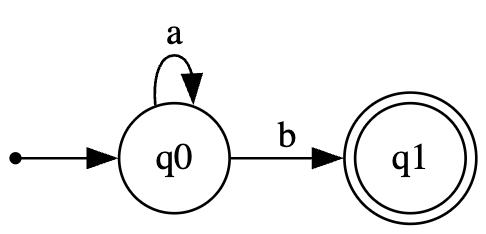
- داخل شکل بالا دایره ها نشان دهنده حالت ها هستن
- دایره $q_0$ یعنی حالت صفرم و شروع که ما همیشه از حالت نقطه یعنی هیچی وارد حالت $q_0$ یعنی شروع میشیم.
- وقتی دایره ما یا به عبارتی حالت ما به شکل دایره با دو خط باشه مثل دایره یا حالت $q_1$ .هر موقع در این حالت بودی و رشته ورودی تمام شد یعنی رشته ورودی جزو زبان بوده و درست است. اما اگر در حالت دایره با یک خط بودیم مثل دایره یا حالت $q_0$ و رشته تمام شد یعنی در حالتی رشته تمام شده که حالت پایان نبوده و رشته ورودی جزو زبان نبوده و غلط است.
- یال ها توابع انتفال ما هستن یا به عبارتی شرط ما برای رفتن از یک حالت به حالت دیگر. الان در مثال شکل بالا ما گفتیم از حالت $q_0$ فقط زمانی میتونی بری به حالت $q_1$ که کاراکتر $b$ رو ببینی. و گفتم اگر کاراکتر $a$ رو دیدی روی همون حالت $q_0$ بمون.
- همچنین اگر در حالتی باشیم مثلا $q_1$ و کاراکتری دریافت کنیم مثل $a$ که تابع انتقالی براش در حالت $q_1$ تعریف نشده ماشین هنگ میکنه و باز به ما میگه رشته غلطه.
خب یادته اجزای ماشین رو اون بالا بهت نشون دادم و گفتم اگه متوجه نمیشی صبر داشته باش
الان میخوام همین ماشین رو با اون اجزایی که گفتم درک کنیم.
گفته بودیم که مجموعه$Q$ مجموعه حالت های ماشین است $$Q = \{ q_0, q_1 \}$$
- ما در این ماشین دو حالت $q_0$ و $q_1$ رو داشتیم دیگه.
مجموعه $\Sigma$ مجموعه کاراکتر های زبان است که به عنوان ورودی داده میشه به ماشین $$ \Sigma = \{a,b\} $$
- ما فقط دو کاراکتر $a$ و $b$ رو داشتیم برای این مثال
و حالت شروع که در همه مثال ها $q_0$ است $$( q_0 ) \Rightarrow Start $$
- در مثال ما هم همین است
مجموعه $F$ که مجموعه حالت های پایان ما است. چرا که میتوان چند حالت برای پایان داشت $$ F(Finish) = \{ q_1 \} $$
- در مثال ما فقط یک حالت پایان داریم و آن هم $q_1$ است
و اما توابع انتقال که به ما میگن از کدام حالت با دیدن کدام کاراکتر به کدام حالت میتوان رفت $$ \delta(q_0, a) = \{ q_0\} $$
- داریم میگیم در حالت $q_0$ که بودی اگر کاراکتر $a$ رو دیدی برو به حالت $q_0$. $$ \delta(q_0, b) = \{ q_1\} $$
- داریم میگیم در حالت $q_0$ که بودی اگر کاراکتر $b$ رو دیدی برو به حالت $q_1$.
البته که این مجموعه ها و علاعم همه برای بیان ریاضی هست و برای امتحان همین کشیدن گراف رو باید بلد بود و کافیه
خب الان بگو ببینم که ایا گراف پایین یک ماشین DFA رو نشون میده یا نه.
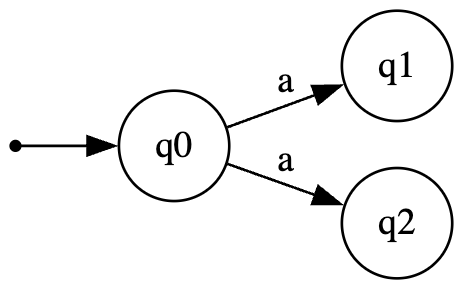
- نه نیست حالا میدونی چرا؟
- چون که ما گفتیم در DFA به ازای یک کاراکتر نمیتوان به دو حالت متفاوت رفت.
- همونطور که میبینی به ازای $a$ از حالت $q_0$ به دو حالت $q_1$ و $q_2$ میره و قاون ماشین DFA رو نقض کرده.
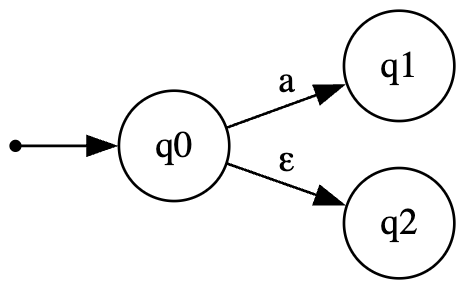
- اینم نیست اگه گفتی چرا؟
- چون ما گفتیم کاراکتر $ε$ که به معنی رشته خالی یا هیچی هست در ماشین DFA مجاز نیست.
- کاراکتر $ε$ بر روی یال میگوید با دیدن رشته خالی میتونی بری به این حالت. که ماشین DFA میگه ما این مسخره بازیا رو نداریم.
- چون ما گفتیم کاراکتر $ε$ که به معنی رشته خالی یا هیچی هست در ماشین DFA مجاز نیست.
خب الان کامل متوجه شدیم که ماشینDFA چطوری رسم میشه الان بریم چند تا مثال حل کنیم.
سوال: ماشین DFA طراحی کنید که رشته هایی با تعداد زوج $a$ را تشخیص دهد($\Sigma = \{a,b\}$).
- داریم میگیم برامون جایگاه $a$ و $b$ مهم نیست و حتی تعداد $b$ هم مهم نیست و تنها چیزی که مهمه اینه که تعداد $a$ ها زوج باشه اگر رشته ورودی این را رعایت کرد ماشین بگه درسته.
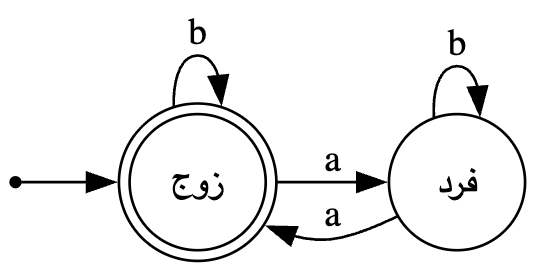
- خب ما برای حل این سوال دو حالت زوج و فرد رو در نظر گرفتیم به این معنی که وقتی در حالت زوج هستیم یعنی تعداد $a$ الان زوج است و اگر در حالت فرد هستیم یعنی تعداد $a$ الان فرد است.
- نکته: لزومی نداره که حتما اسم حالت ها $q_x$ باشه
فرض کنید میخواهیم بررسی کنیم جمله $abaabbbba$ که یک رشته مورد قبول است را ماشین قبول میکند یا نه
| a | b | a | a | b | b | b | b | a |
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
- خب ابتدا در حالت زوج هستیم چرا که هیچ کاراکتری وارد نشده و تعدا $a$ صفر هست و صفر هم زوجه
- بعد با دیدن اولین $a$ یعنی خانه شماره $1$ به حالت فرد میریم.
- بعد در حالت فردیم و با دیدن کاراکتر دوم یعنی $b$ در همان حالت میمانیم طبق چیزی که ماشین گفته.
- بعد با دیدن کاراکتر سوم رشته یعنی $a$ به حالت زوج میریم.
- با دیدن کاراکتر بعدی یعنی دوباره $a$ به حالت فرد میریم.
- با دیدن کاراکتر های پنج تا هشتم در همان حالت فرد میمانیم.
- با دیدن کاراکتر آخر یعنی $a$ به حالت زوج میریم و چون به پایان رشته رسیدیم و کاراکتر دیگری نیست و حالتی که در آن قزار داریم یک دایره دوخط است که یعنی حالت پایان پس ماشین درست برمیگرداند که یعنی رشته مورد قبول است.
حالا بگو ببینم اگه رشته $bba$ رو بدیم چی میشه؟
| b | b | a |
|---|---|---|
| 1 | 2 | 3 |
- در حالت زوج هستیم و با دیدن اولین کاراکتر یعنی $b$ همانجا میمانیم.
- با دیدن دومین کاراکتر چون باز $b$هست همانجا میمانیم.
- با دیدن سومین کاراکتر میریم به حالت فرد چون $a$ دیدیم.
- رشته ما تمام شد و الان ما در یک حالت غیر پایان هستیم ماشین ارور میدهد و میگوید رشته غلط است.
NFA
خب قبل تر گفتیم که:
ماشین
NFAدقیا همان ماشینDFAاست فقط با این تفاوت که:
- در ماشین
NFAمیتوانیم با استفاده از عبارت ε بر سر یال انتقال حالت بگیم که ما میتونیم از این حالت بریم به حالت دیگری بدون دیدن حرفی یا به عبارت دیگه(با دیدن رشته خالی.)- در ماشین
NFAمیتونیم از یک حالت با دیدن یک حرف خاصی مثلا $a$ بریم به چند حالت مختلف و آن محدودیت های ماشینDFAرا نداریم.
مثال
زبان:
$$ L = { w \in {a,b}^* \mid w \text{ ends with } a } $$
ایده:
زبانی که تعداد دلخواه $a$ و $b$ دارد و فقط اگر آخرین حرف a باشد، رشته پذیرفته میشود.
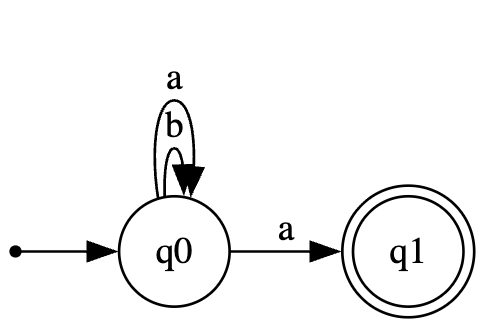
تعریف NFA:
- حالات:
$$ Q = {q_0, q_1} $$ - الفبا:
$$ \Sigma = {a, b} $$ - حالت شروع:
$$ q_0 $$ - حالات نهایی:
$$ F = {q_1} $$
چرا این NFA است؟
چون از حالت $q_0$ با ورودی a میتوان به دو حالت مختلف رفت ($q_0$ و $q_1$). این یعنی غیرقطعی است
چرا این NFA درست است؟
چون گفتیم با دیدن a و b در حالت $q_0$ بمان که این باعث میشود هر ترکیبی با هر تعداد از a و b ساخته شود و در انتها فقط زمانی میتوان به حالت پایان برود که a دیده باشد.
زبان و گرامر مستقل از متن
تعریف ساده
یک زبان را مستقل از متن میگوییم اگر بتوان آن را با یک گرامر مستقل از متن تولید کنیم.
ایدهی اصلی CFG(مستقل از متن)
در این نوع گرامر، قواعد تولید به شکل زیر هستند:
$$ A \rightarrow \alpha $$
که در آن:
- $(A)$ یک متغیر یا غیرپایانه است
- $(\alpha)$ رشتهای از پایانهها و غیرپایانهها است
- نکتهی مهم اینجاست که سمت چپ قاعده فقط یک غیرپایانه است(درست مثل زبان منظم).
- و همچنین محدودیت های زبان منظم را برای سمت راست هر قانون ندارد(پس میتوان گرامر های پیچیده تری نوشت).
تعریف رسمی گرامر مستقل از متن
یک گرامر مستقل از متن به صورت زیر تعریف میشود:
$$ G=(V,\Sigma,R,S) $$
- $(V)$: مجموعه غیرپایانهها
- $(\Sigma)$: مجموعه پایانهها
- $(R)$: مجموعه قواعد تولید
- $(S)$: نماد شروع
مثال 1: زبان پرانتزهای متوازن
زبانی که همهی رشتههای پرانتز درست را تولید میکند:
$$ L={ \text{all balanced parentheses strings} } $$
- مثلاً اینها عضو زباناند
- (())
- ((()))
- (()() )
- ((()()))
یک گرامر مستقل از متن برای این زبان:
$$ S \rightarrow SS \mid (S) \mid \epsilon $$
توضیح قواعد
- $(S \rightarrow SS)$: از این قانون برای قرار دادن پرانتز ها کنار همدیگر استفاده میکنیم
- $(S \rightarrow (S))$: از این قانون برای تولید پرانتز های تو در تو استفاده میکنیم
- $(S \rightarrow \epsilon)$: این قانون رو هم داریم برای خاتمه که به معنی رشته خالی است
نمونه تولید
برای رشتهی (()()):
$$ S \Rightarrow SS \Rightarrow (S)S \Rightarrow ()S \Rightarrow ()(S) \Rightarrow ()() $$
مثال 2: زبان
$$ L={a^n b^n \mid n \ge 0} $$
یعنی تعداد (a)ها و (b)ها برابر باشد و همهی (a)ها قبل از (b)ها بیایند.
- اعضای زبان
- $\epsilon$
- $ab$
- $aabb$
- $aaabbb$
یک CFG برای آن:
$$ S \rightarrow aSb \mid \epsilon $$
چرا درست است؟
- هر بار که از قاعدهی (aSb) استفاده میکنیم:
- یک (a) به اول رشته اضافه میشود
- یک (b) به آخر رشته اضافه میشود
- در نتیجه تعدادشان برابر میماند.
نمونه تولید برای (aaabbb)
$$ S \Rightarrow aSb \Rightarrow aaSbb \Rightarrow aaaSbbb \Rightarrow aaabbb $$
PDA
PDA یک نوع ماشین یا اتوماتای دیگر در نظریهی زبانهاست که مثل اتوماتای متناهی(DFA,NFA) ورودی را میخواند،
اما یک ویژگی خیلی مهم اضافه دارد:
- یک پشته دارد
- پشته مثل یک آرشیو موقت است که ماشین میتواند داخلش چیزی بگذارد یا از آن بردارد.
- پشته هم میدانیم چطوری کار میکند(آخرین چیزی که پوش بشه. اولین چیزیه که پاپ میشه)
چرا پشته مهم است؟
- برای نمایش اتوماتای زبان هایی مثل $a^n b^n$ اتوماتای DFA , NFA ناتوانند زیرا ما برای نمایش این زبان ها نیاز به یک حافظه داریم تا بتواند تعداد $a$ ها را بشمارد و به همان تعداد $b$ قرار دهد.
- اتوماتای پشته ای با داشتن حافظه استک میتواند این کار را برای ما انجام دهد.
تعریف خیلی ساده
PDA مثل یک ماشین حالتدار است که:
-
از روی نوار ورودی، نمادها را یکییکی میخواند
-
یک حالت دارد
-
یک پشته دارد
-
با توجه به:
- نماد ورودی
- نماد بالای پشته
- حالت فعلی
- تصمیم میگیرد چه کار کند
اجزای PDA
یک PDA معمولاً با 7-تایی زیر تعریف میشود:
$$M=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$$
که هر قسمت یعنی:
- $(Q)$: مجموعهی حالتها
- $(\Sigma)$: الفبای ورودی
- $(\Gamma)$: الفبای پشته
- $(\delta)$: تابع انتقال
- $(q_0)$: حالت شروع
- $(Z)$: نماد شروع پشته
- $(F)$: مجموعه حالتهای نهایی
مثال
الان سعی میکنیم با یک مثال این اتوماتای رو خوب یاد بگیریم زبان زیر رو در نظر بگیرید $$ L = { a^n b^n \mid n \ge 1 } $$
اتوماتای آن به شکل زیر است
معکوس کردن زبان (R)
عمل R یا عمل «معکوس» (Reverse) روی یک زبان در نظریه زبانها و ماشینها یعنی اینکه ترتیب حروف تمام رشتههای موجود در آن زبان را وارونه کنیم.
مثال 1
زبان:
$$ L = { ab,, aabb,, 101 } $$
پس معکوس:
$$ L^R = { ba,, bbaa,, 101 } $$
- در رشته 101 چون قرینه است، معکوس همان خود رشته میشود.
مثال 2: زبان بینهایت
فرض کن:
$$ L = { a^n b^n \mid n \ge 1 } $$
یعنی:
- ab
- aabb
- aaabbb
- ...
معکوس:
$$ L^R = { b^n a^n \mid n \ge 1 } $$
پس:
- ba
- bbaa
- bbbaaa
- ...
یسری نکته نکته مهم:
• عمل معکوس روی هر نوع زبانی تعریف میشود (منظم، مستقل از متن و …).
• اگر زبانی منظم باشد، معکوس آن نیز منظم است.
• اگر زبانی مستقل از متن باشد، معکوس آن نیز مستقل از متن است.
مثال 3 — با گرامر (Context-Free Grammar)
فرض کن زبان زیر رو داریم:
$$ L = { a^n b^n \mid n \ge 1 } $$
گرامر زبان L
یک گرامر مستقل از متن برای این زبان:
$$ S \rightarrow aSb \mid ab $$
توضیح:
- هر بار یک (a) اول و یک (b) آخر اضافه میکند.
- در نهایت به (ab) ختم میشود.
مثلاً:
$$ S \Rightarrow aSb \Rightarrow aaSbb \Rightarrow aabb $$
حالا معکوس زبان را میسازیم
میدانیم:
$$ L^R = { b^n a^n \mid n \ge 1 } $$
روش ساخت گرامر معکوس:
کافی است سمت راست همه تولیدها را وارونه کنیم.
گرامر اصلی:
$$ S \rightarrow aSb \mid ab $$
سمت راستها را معکوس میکنیم:
- (aSb) ← میشود ← (bSa)
- (ab) ← میشود ← (ba)
پس گرامر زبان $(L^R)$:
$$ S \rightarrow bSa \mid ba $$
بررسیش میکنیم:
$$ S \Rightarrow bSa \Rightarrow bbSaa \Rightarrow bbaa $$
ماشین تورینگ
ماشینهای قبلی که توی این درس خوندیم (مثل DFA یا PDA) محدودیتهای زیادی داشتن؛ مثلاً حافظهشون کم بود یا ساختار محدودی داشت (مثل پشته). اما ماشین تورینگ قویترین ماشین فرضی هست و هر چیزی که کامپیوترهای امروزی بتونن جادو کنن و حلش کنن، ماشین تورینگ هم میتونه!
اجزای ماشین تورینگ (تصور کن یک نوار کاست قدیمی داریم!)
برای اینکه ماشین تورینگ رو کاملاً درک کنی، فکر کن یک دستگاه قدیمی داری که از ۳ بخش اصلی تشکیل شده:
- یک نوار بیانتها (Tape): یک نوار طولانی که به خونههای مساوی تقسیم شده. داخل هر خونه میتونه یک علامت (مثل
0یا1یاaیاb) نوشته بشه. خونههای خالی هم با یک علامت خاص مثل $\square$ (بلنک یا پوچ) پر شدن. این نوار همون حافظه (RAM) ماشینه. - یک هدِ خواندن و نوشتن (Read/Write Head): این هد روی یکی از خونههای نوار قرار میگیره. کارش چیه؟ میتونه علامت اون خونه رو بخونه، میتونه پاکش کنه و یک علامت جدید بنویسه، و بعد از انجام کارش میتونه یک خونه بره به چپ (L) یا یک خونه بره به راست (R).
- واحد کنترل (بخش وضعیتها یا States): مغز ماشینه که تو هر لحظه میدونه تو چه وضعیتی (مثلاً $q_0$ یا $q_1$) قرار داره و بر اساس جدولی که بهش دادی تصمیم میگیره قدم بعدی چیه.
قانون حرکت ماشین تورینگ:
توی هر قدم، ماشین به وضعیت فعلیش و علامتی که هد داره میخونه نگاه میکنه و ۳ کار انجام میده:
- یک علامت جدید روی نوار مینویسه (یا همون قبلی رو دستنخورده نگه میداره).
- هد رو یک خونه به چپ (L) یا راست (R) حرکت میده.
- خودش میره به یک وضعیت جدید (یا توی همون وضعیت میمونه).
چطور یک ماشین تورینگ بسازیم؟ (حل یک مثال معروف)
بیا با هم مسألهای رو حل کنیم که ماشینهای قبلی (مثل DFA) اصلاً نمیتونستن حلش کنن. مسأله: میخوایم ماشینی بسازیم که زبان $L = {a^n b^n | n \ge 1}$ رو تشخیص بده. یعنی به تعداد مساوی $a$ بیاد و پشت سرش به همون تعداد $b$ بیاد. (مثلاً رشته $aabb$).
استراتژی حل (الگوریتم):
تفکر ماشین تورینگ مثل برنامهنویسی با یک اشارهگر روی آرایهست. بیایم رشته aabb رو روی نوار تصور کنیم:
... ▢ [ a ] [ a ] [ b ] [ b ] ▢ ...
^ (هد اینجاست)
- قدم اول: از چپ شروع کن. اولین $a$ رو که دیدی، تبدیلش کن به $X$ (یعنی این رو شمردم!).
- قدم دوم: حرکت کن به سمت راست، از روی بقیه $a$ها رد شو تا برسی به اولین $b$.
- قدم سوم: اولین $b$ رو که دیدی، تبدیلش کن به $Y$ (یعنی جفتِ اون $a$ رو پیدا کردم!).
- قدم چهارم: حالا دنده عقب بگیر! حرکت کن به سمت چپ، از روی $Y$ها و $a$ها رد شو تا برسی به آخرین $X$ی که ساختی. یک خونه برو راست (میرسی به اولین $a$ باقیمونده).
- تکرار: همین روند رو تکرار کن تا همه $a$ها تبدیل بشن به $X$ و همه $b$ها تبدیل بشن به $Y$.
- پایان: اگر در آخر کار، هیچ $a$ یا $b$ اضافی باقی نمونده بود و همه تبدیل به $X$ و $Y$ شده بودن، ماشین رشته رو قبول (Accept) میکنه.
مثال
میخواهیم ماشینی طراحی کنیم که رشتههایی از حروف $a$ و $b$ رو قبول میکنه که حداقل یک جفت $a$ پشتسرهم (یعنی aa) داخلشون وجود داشته باشه.
- مثلاً رشتههای
baab،aaa،bbaabقبول هستن. - اما رشتههای
ababیاbbbرد میشن چون هیچجا دوتا $a$ به هم نچسبیدن.
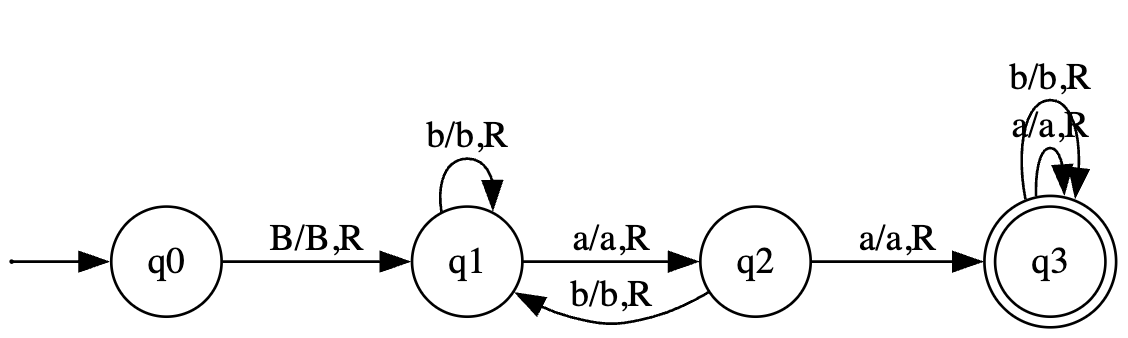
-
معنی نوشته های روی یال ها:
[چی بخون] / [چی بنویس] , [جهت حرکت هد]
نکته: علامت $B$ مخفف Blank (همون خونه خالی نوار $\square$) هست. و بصورت قراردادی هد همیشه در آغاز روی بلانک سمت چپ است.
... ▢ [ a ] [ a ] [ b ] [ b ] ▢ ...
^ (هد اینجاست)
B/B Rیعنی: اگر به خونه خالی نوار (B) رسیدی، دستش نزن و همانBرو باقی بگذار، و برو به راست (R).
تحلیل قدم به قدم وضعیتها (States)
وضعیت $q_0$ (وضعیت شروع)
- یال
B/B Rبه سمت $q_1$: نوار ماشین تورینگ همیشه با یک خونه خالی ($B$) (بلانک) شروع میشه. ماشین در شروع کار این $B$ رو میخونه، کاری بهش نداره و یک خونه میره راست تا برسه به اولین حرف رشته اصلی، و وارد وضعیت $q_1$ میشه.
وضعیت $q_1$ (جستجو برای اولین $a$)
این وضعیت یعنی ماشین داره دنبال اولین $a$ میگرده تا جفتش رو پیدا کنه.
- حلقه روی خودش (
b/b R): تا زمانی که حرفbمیبینه، بیخیال از روش رد میشه و میره راست. ماشین توی همین وضعیت $q_1$ میمونه. - یال
a/a Rبه سمت $q_2$: به محض اینکه اولین حرفaرو دید، میگه «آها! نصف مسیر رو رفتم». از روش رد میشه، میره راست و با خوشحالی میره به وضعیت $q_2$.
وضعیت $q_2$ (کمین برای $a$ دوم)
وقتی ماشین توی $q_2$ هست، یعنی دقیقاً یک قدم قبلش یک $a$ دیده و حالا منتظره ببینه حرف بعدی چیه:
- حالت اول (شکست الگو - یال
b/b Rبه سمت $q_1$): اگر حرف بعدیbباشه، یعنی امیدش ناامید شده (چون رشته شدهabو دوتا $a$ پشت سر هم نیومدن). پس دوباره برمیگرده به وضعیت $q_1$ تا از نو دنبال $a$ بگرده. - حالت دوم (موفقیت الگو - یال
a/a Rبه سمت $q_3$): اگر حرف بعدی دوبارهaباشه، یعنی جفتِaaپیدا شد! پس شرط مسأله برآورده شده. ماشین از روی این $a$ هم رد میشه و با موفقیت میره به وضعیت $q_3$.
وضعیت $q_3$ (وضعیت پذیرش یا همان Accept)
دور $q_3$ دو تا دایره کشیده شده؛ این یعنی وضعیت نهایی (Final State). به محض اینکه ماشین پاش رو بذاره توی این وضعیت، یعنی رشته مورد قبوله. از اینجا به بعد دیگه مهم نیست چه حروف دیگهای روی نوار بیان.
